CHIPKIT: 2nd Tutorial on Agile Research Test Chips @ISCA’20
Paul Whatmough (Arm Research/Harvard), Marco Donato (Harvard), Glenn Ko (Harvard), Sae-Kyu Lee (IBM Research), David Brooks (Harvard), and Gu-Yeon Wei (Harvard)
Updates
31st May 2020, 10am-1pm EDT - Live Q&A session. Pre-recorded videos available during the conference via the Whova app.
Overview
Research test chips are the ultimate experiment to demonstrate the true value of novel computer architecture innovations. They are always very highly regarded by reviewers as the most honest evaluation of a new hardware proposal. In addition, there is a huge pedagogical value in taping out test chips, as it offers insight on the impact of real hardware and microarchitecture details that are critical in guiding higher level architecture decisions and trade offs. Nonetheless, despite all this, taping out test chips remains a challenge for those who are following this path for the first time. Traditionally, research chips have been time consuming to design, fabricate and test, and often error prone - potentially requiring re-spins to fix problems.
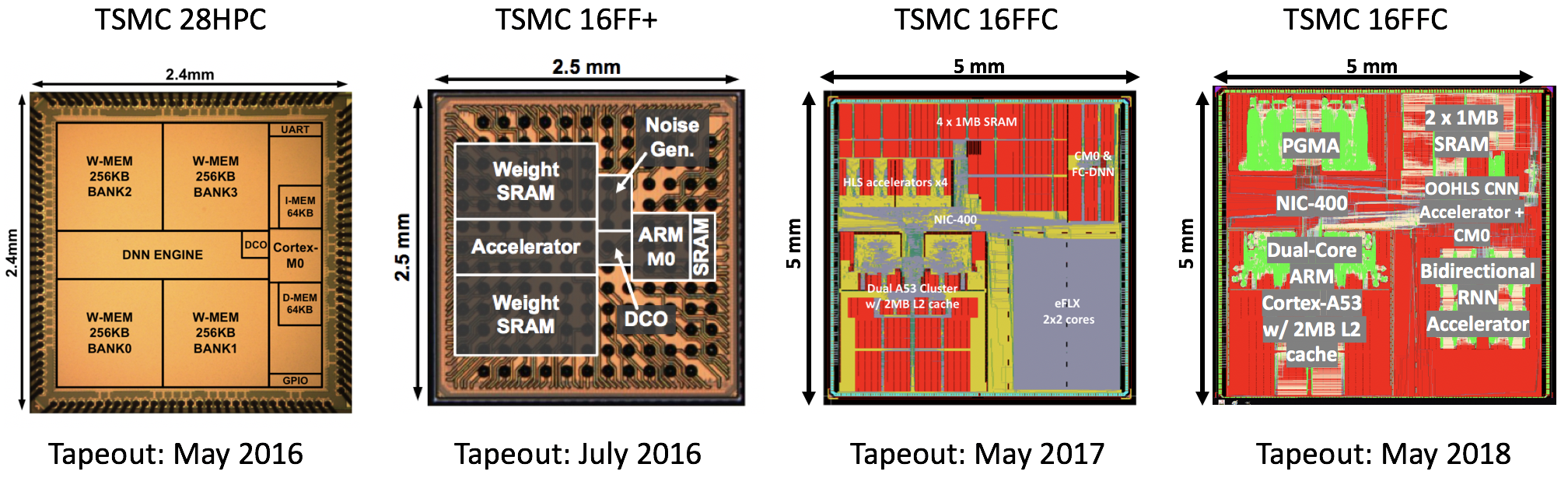
This tutorial sets out to present a clear and straightforward template for a modern design flow for rapid, agile, and successful tape out of research test chips. We describe a front-to-back design example, drawing on many generations of test chips (shown in the illustration below) following a consistent design approach [2], [3], [4], [5], [6]. To help researchers start up their own SoC designs, the content of this tutorial is supported with the release of our CHIPKIT project[1], which provides a comprehensive set of open source resources for the design and implementation of research tapeouts. The project includes a sample SoC design which leverages this design methodology for demonstrating novel specialized hardware architectures, using the CHIPKIT infrastructure.
Open Source Project [Github]
Companion Paper [IEEEXplore] [Arxiv]
Tutorial Outline
Part 1: CHIPKIT: An agile, reusable open-source framework for rapid test chip development
"Introduction", Paul Whatmough
* Who are we? * Why build test chips in academia? * Goals of the tutorial * Different types of test chips * Some recent Harvard test chips"M-Class (Microcontroller) SoC Development", Paul Whatmough
* Opportunities for agile and reusable design * SoC bus fabrics * Off-chip interfaces * On-chip memories * Clocks, resets and power domains"A-Class (Apps Processor) SoC Development", Marco Donato
Abstract (TBD)"Custom IP Development", Paul Whatmough
* Overview * Interface and control * Hardware description * SystemVerilog coding guidelines"Physical Design", Glenn Ko
Abstract (TBD)"Bring up and Testing", Marco Donato
Abstract (TBD)Part 2: Invited talks on agile chip design from the architecture community
"OpenROAD: An open-source RTL-to-GDS tool with advanced-node capability", Andrew Kahng (UCSD)
Open-source EDA boosts the lifecycle and robustness of academic EDA research while providing a bridge to industrial design practice. For architects and IC designers, open-source tool chains can enable early prototyping and design space exploration, and can help bring ideas to manufacturing-ready layout with reduced schedule and cost. We will give an overview and demo of the forthcoming v1.0 release (July 2020) of RTL-to-GDS automation from the OpenROAD project. The talk will also note relevant aspects of tool architecture, database, software engineering, and potential synergies with future hardware and architecture innovation. Slides
"PyMTL3: A Python Framework for Open-Source Hardware Modeling, Generation, Simulation, and Verification", Christopher Batten (Cornell)
PyMTL3 is a new Python-based framework for hardware modeling, generation, simulation, and verification well suited to implementing computer architecture test chips. PyMTL2 was developed several years ago and has been used extensively in research, teaching, and prototyping. PyMTL3 retains some of the best features of PyMTL2 including: support for highly paramterized accelerator generators; a unified framework for functional-, cycle-, and register-transfer level modeling; pure-Python-based simulation; elegant translation of PyMTL RTL to Verilog RTL; and first-class support for co-simulation of PyMTL and Verilog models through Python/Verilator integration. PyMTL3 additionally includes a completely new execution model based on hierarchical static scheduling of concurrent sequential update blocks; improved simulation performance; first-class support for method-based interfaces; PyMTL passes for analyzing, instrumenting, and transforming PyMTL models; and improved verification methodologies. This talk will introduce the PyMTL3 framework and walk-through a hands-on demo illustrating some of the more basic features for register-transfer-level modeling with PyMTL3. Slides
"Predictable Accelerator Design", Adrian Sampson (Cornell)
We need to make it easier to design custom accelerators, especially for reconfigurable hardware (i.e., FPGAs). RTL design is too low level for most domain experts. The best current alternative is C-based high-level synthesis (HLS). The thesis of this talk is that far better programming models than traditional HLS are possible. Repurposing a legacy software language for hardware design inevitably introduces a semantic chasm and concomitant usability pitfalls; we demonstrate empirically that HLS can be *unpredictable* in the sense that small, innocuous-seeming source code changes can lead to large, counter-intuitive swings in the area and latency of the generated hardware. We are working on a programming language, Dahlia, that uses a type system to restrict accelerator designs to a subset with predictable performance. Based on Dahlia, we are designing a compiler infrastructure to bring predictable hardware generation to any DSL. Slides
"Closing the algorithm/hardware design and verification loop with speed via high-level synthesis", Thierry Tambe (Harvard)
The waning effectiveness of Moore’s law has spurred the rise of application-driven architectures as CMOS scaling no longer provides the power and performance fruits it once did. In order to keep delivering energy efficiency gains, specialized SoCs are exhibiting skyrocketing design complexity with development efforts increasing each generation as a result. In this talk, we will shed light on an agile algorithm-hardware co-design and co-verification methodology powered by high-level synthesis (HLS), which enabled us to reduce front-end VLSI design efforts by orders of magnitude. We will provide some background and share details on best known practices, pitfalls to avoid, and overall learnings from a high-productivity digital VLSI flow which leverages HLS in order to efficiently close the loop between the software modeling and the frontend hardware implementation. Slides
"Arm Academic Enablement Programs", Shuojin Hang (Arm)
At Arm, we value academic-industry collaboration as a driving factor of our ever-evolving industry. As a result, we endeavour to lower the barriers for researchers and educators to access and harness our technologies. In this session, I will talk about the Education and Research Enablement Kits that are serving universities and institutions worldwide. I will also explain how academics can access a plethora of Arm IPs for research and education purposes. Slides
Previous Tutorials
BibTeX
If you find this tutorial material useful for your research, please consider citing our companion paper:
@ARTICLE{chipkit_micro2020,
author={P. {Whatmough} and M. {Donato} and G. {Ko} and S. K. {Lee} and D. {Brooks} and G. {Wei}},
journal={IEEE Micro},
title={CHIPKIT: An agile, reusable open-source framework for rapid test chip development},
year={2020},
volume={},
number={},
pages={1-1},}
References
[1] P. N. Whatmough, M. Donato, G. Ko, S. K. Lee, D. Brooks, and G. Wei, in IEEE Micro, 2020
[3] P. N. Whatmough, S. K. Lee, D. Brooks and G. Wei, in IEEE Journal of Solid-State Circuits, 2018
[5] S. K. Lee, P. N. Whatmough, D. Brooks and G. Wei, in IEEE Journal of Solid-State Circuits, 2019
Organizers and Affiliations
 Paul Whatmough, Arm Research: Paul N. Whatmough received the B.Eng. degree (first class Hons.) from the University of Lancaster, in 2003, the M.Sc. degree (with distinction) from the University of Bristol, in 2004, and the Doctorate degree in electronic engineering from University College London, in 2012, all in the UK. He currently leads research on hardware for machine learning at Arm ML Research group in Boston, MA, and is a part-time Associate at Harvard University, MA. He has taped out more than a dozen chips to date, in industrial and academic research groups. Contact me on at paul.whatmough@arm.com
Paul Whatmough, Arm Research: Paul N. Whatmough received the B.Eng. degree (first class Hons.) from the University of Lancaster, in 2003, the M.Sc. degree (with distinction) from the University of Bristol, in 2004, and the Doctorate degree in electronic engineering from University College London, in 2012, all in the UK. He currently leads research on hardware for machine learning at Arm ML Research group in Boston, MA, and is a part-time Associate at Harvard University, MA. He has taped out more than a dozen chips to date, in industrial and academic research groups. Contact me on at paul.whatmough@arm.com
 Marco Donato, Harvard University: Marco Donato received his B.S. and M.S. (cum laude) in Electrical Engineering from the University of Rome “La Sapienza”, Italy, in 2008 and 2010, respectively, and his Ph.D. in Electrical Sciences and Computer Engineering from Brown University in 2016. In 2017, he joined Harvard University. His research interests include modeling and analysis of noise sources in nanoscale circuits, and automated tools for noise-tolerant circuit architectures. He is currently working on the design of novel embedded memory subsystems and circuitry in advanced CMOS technology nodes with applications to machine learning hardware accelerator SoCs.
Marco Donato, Harvard University: Marco Donato received his B.S. and M.S. (cum laude) in Electrical Engineering from the University of Rome “La Sapienza”, Italy, in 2008 and 2010, respectively, and his Ph.D. in Electrical Sciences and Computer Engineering from Brown University in 2016. In 2017, he joined Harvard University. His research interests include modeling and analysis of noise sources in nanoscale circuits, and automated tools for noise-tolerant circuit architectures. He is currently working on the design of novel embedded memory subsystems and circuitry in advanced CMOS technology nodes with applications to machine learning hardware accelerator SoCs.
 Glenn G. Ko, Harvard University: Glenn G. Ko is a postdoctoral researcher at Harvard University working with Professor Gu-Yeon Wei and Professor David Brooks. He received B.S. and M.S. in Electrical and Computer Engineering, from the University of Illinois at Urbana-Champaign in 2004 and 2006 respectively. He then joined Samsung Electronics where he designed Samsung Exynos application processor SoCs. He returned to Illinois and received Ph.D. in Electrical and Computer Engineering in 2017 before joining Harvard University in 2018. He has also spent summers at Qualcomm Research and IBM Research on machine learning and architecture research. His current research interests are machine learning, algorithm-hardware co-design and scalable accelerator architectures on the cloud and edge devices.
Glenn G. Ko, Harvard University: Glenn G. Ko is a postdoctoral researcher at Harvard University working with Professor Gu-Yeon Wei and Professor David Brooks. He received B.S. and M.S. in Electrical and Computer Engineering, from the University of Illinois at Urbana-Champaign in 2004 and 2006 respectively. He then joined Samsung Electronics where he designed Samsung Exynos application processor SoCs. He returned to Illinois and received Ph.D. in Electrical and Computer Engineering in 2017 before joining Harvard University in 2018. He has also spent summers at Qualcomm Research and IBM Research on machine learning and architecture research. His current research interests are machine learning, algorithm-hardware co-design and scalable accelerator architectures on the cloud and edge devices.
 Sae Kyu Lee, IBM Research: Sae Kyu Lee received his B.S. degree in Electrical Engineering from Seoul National University, Seoul, Republic of Korea, the M.S. degree in Electrical and Computer Engineering from The University of Texas at Austin, Austin, TX, USA, and the Ph.D. degree from Harvard University, Cambridge, MA, USA. He was previously with Intel Corporation, Austin, TX, USA, and Advanced Micro Devices, Boxbor-ough, MA, USA, where he worked on mobile microprocessor design. He is currently with IBM T.J. Watson Research Center, Yorktown Heights, NY, USA. His research interests include energy-efficient accelerator design for machine learning applications and VLSI design for efficient on-chip power delivery solutions.
Sae Kyu Lee, IBM Research: Sae Kyu Lee received his B.S. degree in Electrical Engineering from Seoul National University, Seoul, Republic of Korea, the M.S. degree in Electrical and Computer Engineering from The University of Texas at Austin, Austin, TX, USA, and the Ph.D. degree from Harvard University, Cambridge, MA, USA. He was previously with Intel Corporation, Austin, TX, USA, and Advanced Micro Devices, Boxbor-ough, MA, USA, where he worked on mobile microprocessor design. He is currently with IBM T.J. Watson Research Center, Yorktown Heights, NY, USA. His research interests include energy-efficient accelerator design for machine learning applications and VLSI design for efficient on-chip power delivery solutions.
 David Brooks, Harvard University: David Brooks is the Haley Family Professor of Computer Science in the School of Engineering and Applied Sciences at Harvard University. Prior to joining Harvard, he was a research staff member at IBM T.J. Watson Research Center. Prof. Brooks received his BS in Electrical Engineering at the University of Southern California and MA and PhD degrees in Electrical Engineering at Princeton University. His research interests include resilient and power-efficient computer hardware and software design for high-performance and embedded systems. Prof. Brooks is a Fellow of the IEEE and has received several honors and awards including the ACM Maurice Wilkes Award and ISCA Influential Paper Award.
David Brooks, Harvard University: David Brooks is the Haley Family Professor of Computer Science in the School of Engineering and Applied Sciences at Harvard University. Prior to joining Harvard, he was a research staff member at IBM T.J. Watson Research Center. Prof. Brooks received his BS in Electrical Engineering at the University of Southern California and MA and PhD degrees in Electrical Engineering at Princeton University. His research interests include resilient and power-efficient computer hardware and software design for high-performance and embedded systems. Prof. Brooks is a Fellow of the IEEE and has received several honors and awards including the ACM Maurice Wilkes Award and ISCA Influential Paper Award.
 Gu-Yeon Wei, Harvard University: Gu-Yeon Wei is Robert and Suzanne Case Professor of Electrical Engineering and Computer Science in the Paulson School of Engineering and Applied Sciences (SEAS) at Harvard University. He received his BS, MS, and PhD degrees in Electrical Engineering from Stanford University. His research interests span multiple layers of a computing system: mixed-signal integrated circuits, computer architecture, and design tools for efficient hardware. His research efforts focus on identifying synergistic opportunities across these layers to develop energy-efficient solutions for a broad range of systems from flapping-wing microrobots to machine learning hardware for IoT devices to large-scale servers.
Gu-Yeon Wei, Harvard University: Gu-Yeon Wei is Robert and Suzanne Case Professor of Electrical Engineering and Computer Science in the Paulson School of Engineering and Applied Sciences (SEAS) at Harvard University. He received his BS, MS, and PhD degrees in Electrical Engineering from Stanford University. His research interests span multiple layers of a computing system: mixed-signal integrated circuits, computer architecture, and design tools for efficient hardware. His research efforts focus on identifying synergistic opportunities across these layers to develop energy-efficient solutions for a broad range of systems from flapping-wing microrobots to machine learning hardware for IoT devices to large-scale servers.